spring
nuxt.js
lamda表达式
华为机试
hbase调优
node
材质
webpack
Shader
负载均衡
kmeans
引用
MySQL集群搭建
概率论
jQuery
程序员40
敖丙
NTF
nvidia
主从复制
视频生成
2024/4/12 17:29:18
视频生成: 基于Stable Diffusion的微调方法
chatGPT带来了几个月的AIGC热度,文本图像生成模型大行其道,但AI在视频生成任务上尚没有较好的开源仓库,并受限于“缺那么几百块A100"的资源问题,大多数人无法展开视频生成的研究。好在目前有不少针对视频生成的相关paper&…


【SIGGRAPH 2023】解读Rerender A Video:Zero-Shot 视频翻译任务
Diffusion Models视频生成-博客汇总 前言:Video-to-Video是视频生成中非常火的任务,也是最有应用价值的方向。图形学顶会SIGGRAPH 2023有一篇经典论文《Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation》,其中关键帧翻译、跨帧约束等方法值得我们借鉴。…

AI之Sora:Sora(文本指令生成视频的里程碑模型)的简介(能力/安全性/技术细节)、使用方法、案例应用之详细攻略
AI之Sora:Sora(文本指令生成视频的里程碑模型)的简介(能力/安全性/技术细节)、使用方法、案例应用之详细攻略 导读:Sora 是OpenAI研发的一个可以根据文字描述生成视频的AI模型。它的主要特性、功能以及OpenAI在安全和应用方面的策略的核心要点如下所示&a…

OpenAI视频生成模型Sora的全面解析:从扩散Transformer到ViViT、DiT、NaViT、VideoPoet
前言
真没想到,距离视频生成上一轮的集中爆发(详见《视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0、W.A.L.T》)才过去三个月,没想OpenAI一出手,该领域又直接变天了
自打2.16日OpenAI发布sora以来,不…
OpenAI视频生成模型Sora的全面解析:从ViViT、扩散Transformer到NaViT、VideoPoet
前言
真没想到,距离视频生成上一轮的集中爆发(详见《视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0、W.A.L.T》)才过去三个月,没想OpenAI一出手,该领域又直接变天了
自打2.16日OpenAI发布sora以来(其开发团队包…
Diffusion Models可控视频生成Control-A-Video:论文和源码解读
Diffusion Models专栏文章汇总:入门与实战 前言:Diffusion视频生成的时间连贯性问题是可控视频生成问题最大的挑战。Control-A-Video提出的时空一致性建模法、残差噪声初始化法和首帧定型法能有效解决这一问题,非常值得我们借鉴。博主详细解读论文和代码,并给出一些自己的思…

Follow-Your-Click——点选图像任意区域对象使用短提示语即可生成视频
简介
“I2V”(图像到视频生成)旨在将静态图像转换为具有合理动作的动态视频剪辑,在电影制作、增强现实和自动广告等领域有广泛应用。然而,现有的I2V方法存在一些问题,例如缺乏对图像中需要移动的部分的精准控制&#…

Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
目录
论文地址:Mora: Enabling Generalist Video Generation viaA Multi-Agent Framework github地址:https://github.com/lichao-sun/Mora
一、摘要
(1)Mora 的主要特点:
(2)Mora的应用场景…
Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频生成器
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators Paper: https://arxiv.org/abs/2303.13439 Project: https://github.com/Picsart-AI-Research/Text2Video-Zero 原文链接:Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频…
Open AI 的 Sora 是什么?它是如何工作的?应用场景、风险、替代方案、未来意义等
Open AI 的 Sora 是什么?它是如何工作的?应用场景、风险、替代方案、未来意义等 探索 OpenAI 的 Sora:一种突破性的文本到视频 AI,将在 2024 年彻底改变多模态人工智能。探索其功能、创新和潜在影响。 OpenAI 最近宣布了其最新的突…
CV计算机视觉每日开源代码Paper with code速览-2023.10.30
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【语义分割】(NeurIPS2023)SmooSe…
三十六亿的《哪吒》历时五年,动画创作难如何解决?
原创:HyperAI超神经 关键词:哪吒 动画电影 自动上色 视频生成 哪吒又双叒叕破纪录了!
电影《哪吒之魔童降世》自 7 月 26 日上映以来,一直在刷新动画电影的票房纪录。截止目前,19 天里全网票房突破 36 亿…
文生视频领域SOTA工作Make-A-Video:论文解读和代码赏析
Diffusion Models专栏文章汇总:入门与实战 前言:2022年年底Meta AI提出了Make-A-Video,一年过去了依旧是文生视频领域的SOTA工作,在主流数据集上依旧保持着最先进的指标。论文利用了预训练的Text-to-Image模型扩展到Text-to-Video任务,大大降低了视频生成的门槛;论文中提…
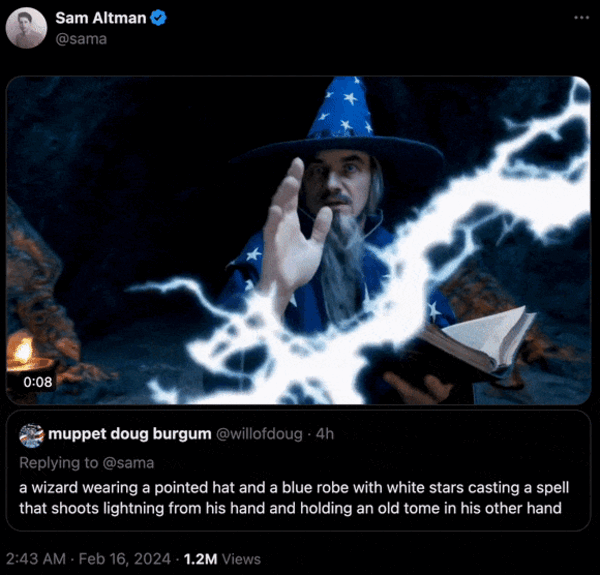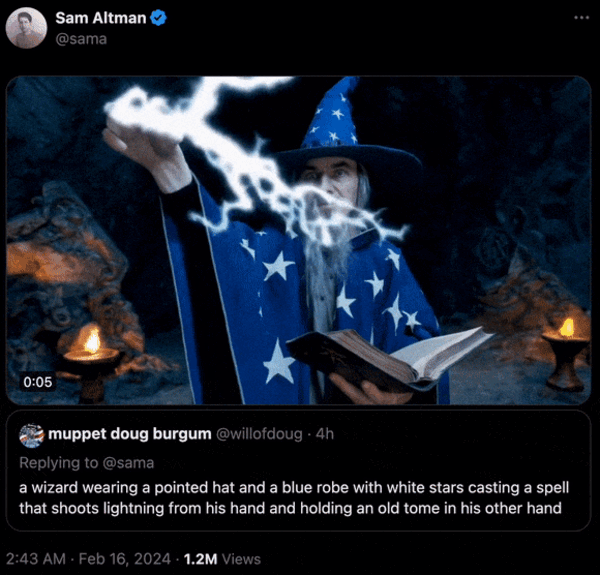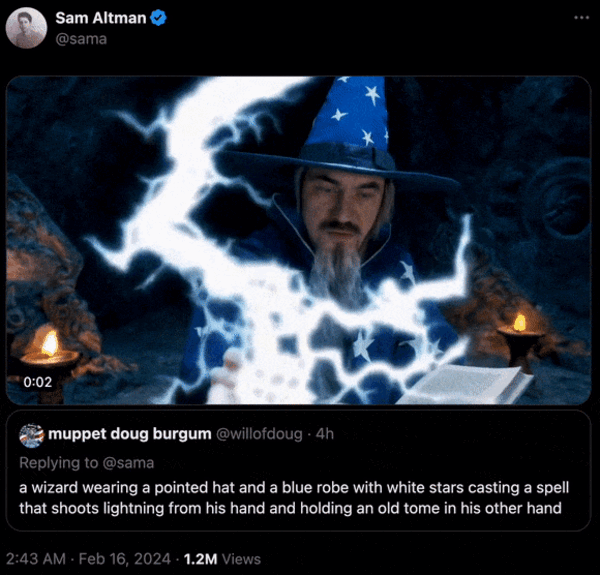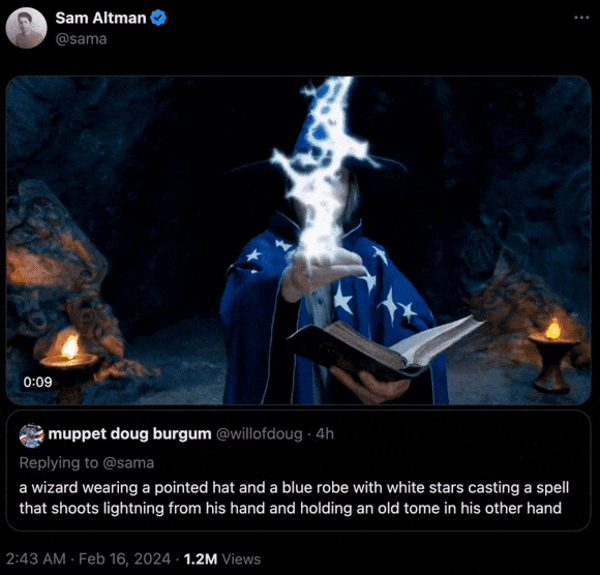
软件工程师,OpenAI Sora驾到,快来围观
概述 近期,OpenAI在其官方网站上公布了Sora文生视频模型的详细信息,展示了其令人印象深刻的能力,包括根据文本输入快速生成长达一分钟的高清视频。Sora的强大之处在于其能够根据文本描述,生成长达60秒的视频,其中包含&…
Meta最新视频生成工具:emu video技术报告解读
Diffusion Models视频生成-博客汇总 前言:去年Meta推出了make-a-video,过去了一年多仍然是视频生成领域的SOTA。最近Meta又推出了更强的视频生成模型EMU Video,刷新了多项指标。这篇博客解读一下背后的论文《EMU VIDEO: Factorizing Text-to-Video Generation by Explicit I…

CVPR 2024中有哪些值得关注的视频生成和视频编辑方向的论文?
Diffusion Models视频生成-博客汇总 前言:轰轰烈烈的CVPR 2024所有accept paper已经全部公开,随着Sora的爆火,视频生成和视频编辑是目前计算机视觉最火热的方向,受到了很多人的关注。这篇博客就整理盘点一下有哪些值得关注的视频生成和视频编辑方向的论文?值得做这个方向的…
深度解读:如何解决Image-to-Video模型视频生成模糊的问题?
Diffusion Models视频生成-博客汇总 前言:目前Image-to-Video的视频生成模型,图片一般会经过VAE Encoder和Image precessor,导致图片中的信息会受到较大损失,生成的视频在细节信息上与输入的图片有较大的出入。这篇博客结合最新的论文和代码,讲解如何解决Image-to-Video模…

解读电影级视频生成模型 MovieFactory
Diffusion Models视频生成-博客汇总 前言:MovieFactory是第一个全自动电影生成模型,可以根据用户输入的文本信息自动扩写剧本,并生成电影级视频。其中针对预训练的图像生成模型与视频模型之间的gap提出了微调方法非常值得借鉴。这篇博客详细解…
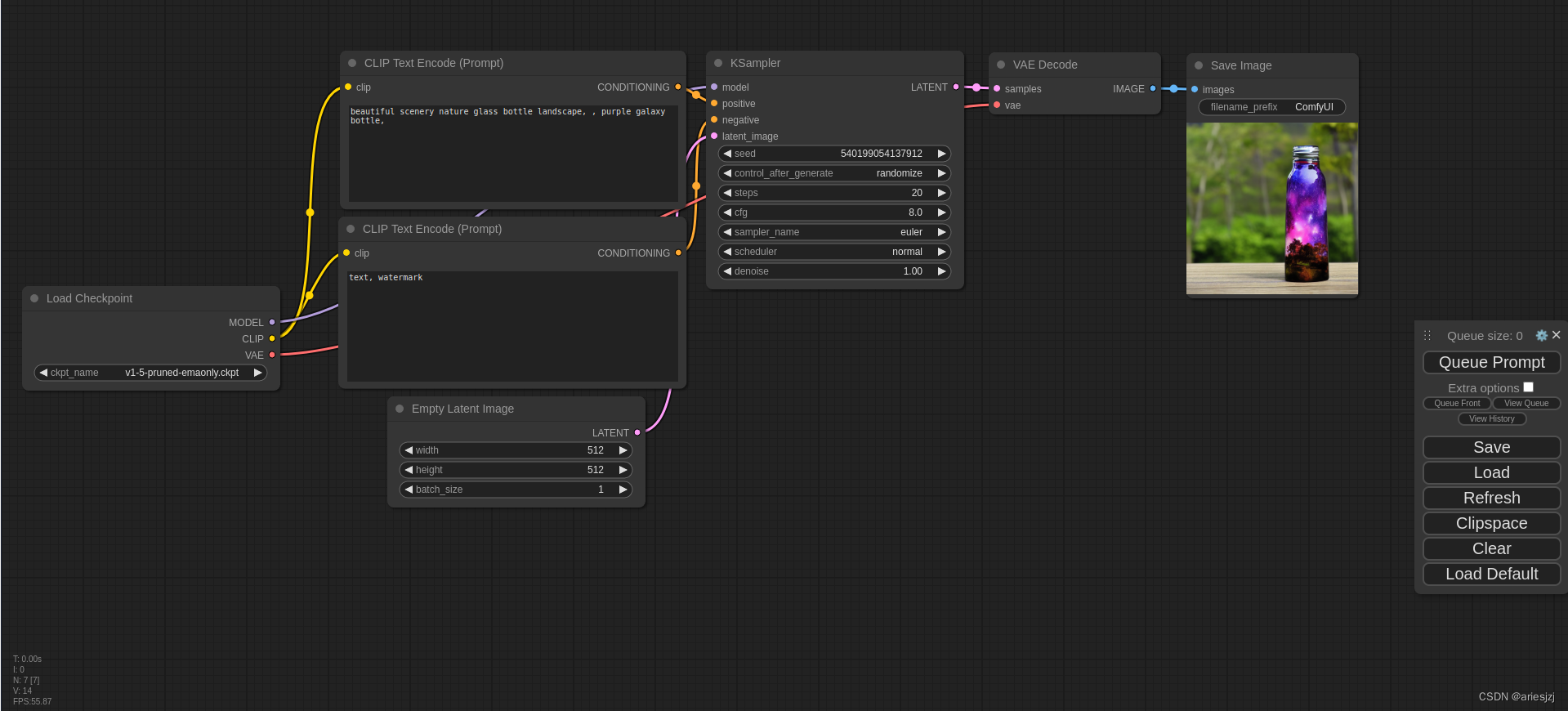
本地用AIGC生成图像与视频
最近AI界最火的话题,当属Sora了。遗憾的是,Sora目前还没开源或提供模型下载,所以没法在本地跑起来。但是,业界有一些开源的图像与视频生成模型。虽然效果上还没那么惊艳,但还是值得我们体验与学习下的。
Stable Diffu…
CVPR2024|AIGC(图像生成,视频生成等)相关论文汇总(附论文链接/开源代码/解析)【持续更新】
CVPR2024|AIGC相关论文汇总(如果觉得有帮助,欢迎点赞和收藏) Awesome-CVPR2024-AIGC1.图像生成(Image Generation/Image Synthesis)ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image GenerationsInstanceDiffusion: …
【NeurIPS 2023】多模态联合视频生成大模型CoDi
Diffusion Models视频生成-博客汇总 前言:目前视频生成的大部分工作都是只能生成无声音的视频,距离真正可用的视频还有不小的差距。CoDi提出了一种并行多模态生成的大模型,可以同时生成带有音频的视频,距离真正的视频生成更近了一步。相信在不远的将来,可以AI生成的模型可…

MagicVideo-V2:多阶段高保真视频生成框架
本项工作介绍了MagicVideo-V2,将文本到图像模型、视频运动生成器、参考图像embedding模块和帧内插模块集成到端到端的视频生成流程中。由于这些架构设计的好处,MagicVideo-V2能够生成具有极高保真度和流畅度的美观高分辨率视频。通过大规模用户评估&…
AIGC专栏8——EasyPhoto 视频领域拓展-让AIGC肖像动起来
AIGC专栏8——EasyPhoto 视频领域初拓展-让AIGC肖像动起来 学习前言源码下载地址技术原理储备Video Inference 功能说明 & 效果展示1、Text2Video功能说明a、实现原理简介b、文到视频UI介绍c、结果展示 2、Image2Video功能说明a、实现原理简介i、单图模式ii、首尾图模式 b、…
代码解读:Zero-shot 视频生成任务 Text2Video-Zero
Diffusion Models视频生成-博客汇总 前言:上一篇博客《【ICCV 2023 Oral】解读Text2Video-Zero:解锁 Zero-shot 视频生成任务》解读了这篇论文《Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators》。这篇论文的创新点比较多,含金量很高,而…

【SVD生成视频+可本地部署】ComfyUI使用(二)——使用Stable Video Diffusion生成视频 (2023.11开源)
SVD官方主页 : Huggingface | | Stability.ai || 论文地址 huggingface在线运行demo : https://huggingface.co/spaces/multimodalart/stable-video-diffusion SVD开源代码:Github(含其他项目) || Huggingface 在Comfyui使用&…
2024年Diffusion Models还有哪些方向值得研究(好发论文)?
Diffusion Models专栏文章汇总:入门与实战 前言:笔者follow扩散模型的科研进展已经将近3年了,见证了diffusion从无人问津到炙手可热的过程。当下扩散模型还有哪些缺点?还有哪些需要改进的方向?还有哪些方向值得研究?还有哪些方向好发论文?不知不觉时间已经来到了2024年,…

gen1-视频生成论文阅读
文章目录 摘要贡献算法3.1 LDM3.2 时空隐空间扩散3.3表征内容及结构内容表征结构表征条件机制采样 3.4优化过程 实验结果结论 论文:
《Structure and Content-Guided Video Synthesis with Diffusion Models》 官网:
https://research.runwayml.com/ge…
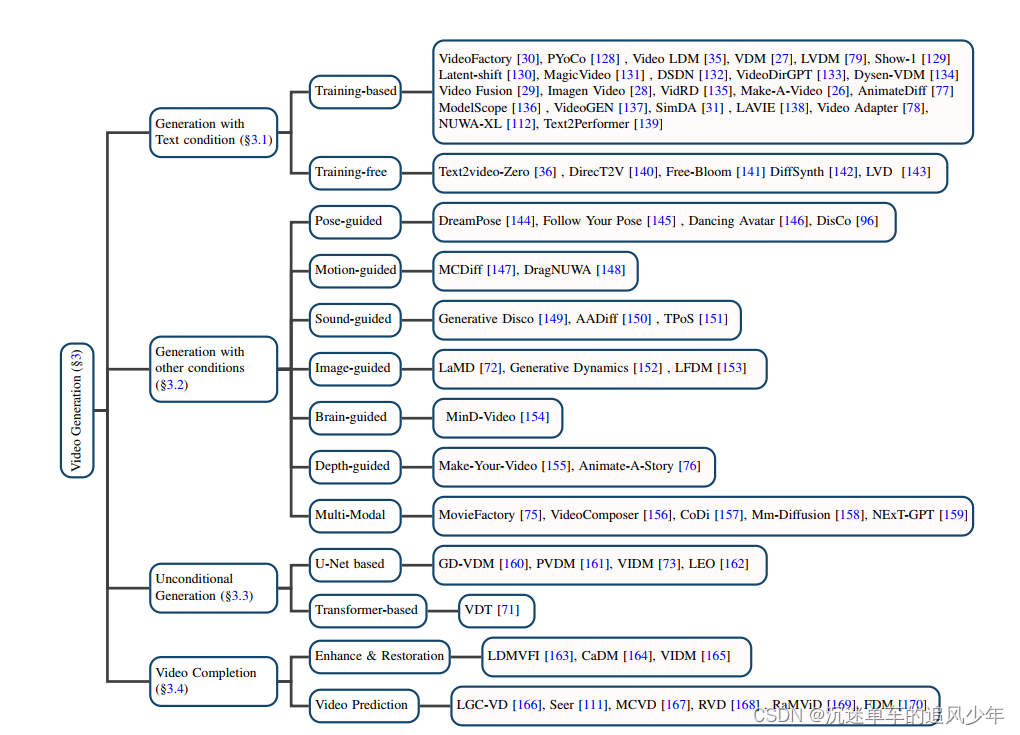
Diffusion Models视频生成-博客汇总
0、【论文汇总】Diffusion Models视频生成/视频编辑/可控视频生成/跨模态视频生成 本文总结了Diffusion Models视频生成领域相关的工作,目前共收录142篇,持续更新中。 1、Video Diffusion Models:基于扩散模型的视频生成 扩散模型已经被广泛运用到图像生成、image-to-image转…

OpenAI视频生成模型Sora背后的技术及其深远的影响
前言
Sora的视频生成技术在保真度、长度、稳定性、一致性、分辨率和文字理解等方面都达到了当前最优水平。其核心技术包括使用视觉块编码将不同格式的视频统一编码成Transformer可训练的嵌入向量,以及类似于扩散过程的UNet方法进行降维和升维的加噪与去噪操作。通过…
【CVPR 2022】解读 Controllable Animation of Fluid Elements in Still Images:光流法视频生成
Diffusion Models视频生成-博客汇总 前言:用户输入箭头,就能让图像动起来,这是经典的Animating任务。CVPR 2022中的一篇经典论文《Controllable Animation of Fluid Elements in Still Images》使用光流法做这种image-to-video任务,很多做法值得借鉴,这篇博客详细这篇论文…
Stable Diffusion的结构要被淘汰了吗?详细解读谷歌最新大杀器VideoPoet
Diffusion Models视频生成-博客汇总 前言:视频生成领域长期被Stable Diffusion统治,大部分的方式都是在预训练的图片Stable Diffusion的基础上加入时间层,学习动态信息。虽然有CoDi《【NeurIPS 2023】多模态联合视频生成大模型CoDi》等模型尝试过突破这一结构的局限,但是都…
笔记:Pika Labs 3D 动画生成工具
Pika Labs 一款3D 动画生成工具 本文地址:https://blog.csdn.net/qq_28550263/article/details/134657306 目 录 1. 简介2. 准备2.1 安装 discord2.2 加入 Discord 频道 3. Pika 使用指南2.1 快速开始2.2 从图像到视频2.3 Pika Bot按钮2.4 提示(Prompt&a…
解读VideoComposer:多模态融合视频生成
Diffusion Models视频生成-博客汇总 前言:达摩院出品的VideoComposer,是Composer家族的重要成员,开辟了组合多种模态特征生成视频的先河。重要的是开源了推理代码和模型,利于后人研究。这篇博客详细解读一下VideoComposer论文原理。 目录
贡献概述
方法详解
多模态特征融…
【CVPR 2023】Diffusion Models高分辨率长视频生成 Align your Latents
Diffusion Models专栏文章汇总:入门与实战 前言:CVPR 2023年的工作《Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models》实现了高帧率高分辨率长视频生成,并在保持时间一致性上做了很多工作。这篇博客详细解读一下背后的原理,并总结一下…
解读DreamPose:基于Diffusion Models的模特视频生成
Diffusion Models视频生成-博客汇总 前言:谷歌研究院联合英伟达提出了DreamPose,通过修改起点噪声融入姿态信息,并微调VAE-CLIP adapter注入图片信息,做到pose&image-to-video的效果。是少数扩散模型中image-to-video的工作,这篇博客详细解读一下这篇论文《DreamPose:…

多模态——使用stable-video-diffusion将图片生成视频
多模态——使用stable-video-diffusion将图片生成视频 0. 内容简介1. 运行环境2. 模型下载3. 代码梳理3.1 修改yaml文件中的svd路径3.2 修改DeepFloyDataFiltering的vit路径3.3 修改open_clip的clip路径3.4 代码总体结构 4. 资源消耗5. 效果预览 0. 内容简介
近期,…
解读Sketching the Future (STF):零样本条件视频生成
Diffusion Models视频生成-博客汇总 前言:基于草图的视频生成目前是一个基本无人探索过的领域,videocomposer做过一些简单的探索。Sketching the Future从零样本条件视频生成出发,出色的完成了这一任务。这篇博客就解读一下《Sketching the Future (STF): Applying Conditio…